
Коли ви робите покупки в інтернет-магазині, ви залишаєте дані про себе. Дані створюються під час тестування автомобілів, щоразу, коли ви користуєтеся ліфтом, а також коли хтось перевіряє товари, що надходять на склад. Ці дані можуть бути оформлені в знання, необхідні для досягнення успіху.
Щоб добути золото, вам потрібне не везіння, а глибинний аналіз. Виявлені закономірності у великій кількості даних дійсно можуть бути на вагу золота. Така інформація допомагатиме малому та середньому бізнесу краще обслуговувати своїх клієнтів, покращити ефективність виробництва, оптимізувати ланцюжок постачання, підвищити якість продукції та скоротити час простоїв.
Amazon, наприклад, використовує інтелектуальний аналіз даних, аби пропонувати товари: клієнти, які купили певну книгу, купують і ось цю. Такі рекомендації збільшують продажі інтернет-магазину приблизно на третину.
Виробник ліфтів Otis аналізує дані в поєднанні з машинним навчанням для здійснення «прогностичного обслуговування». Завдяки цьому покращується життєвий цикл ліфтів і підвищується рівень задоволеності клієнтів.
Що таке глибинний аналіз даних
Глибинний аналіз даних (Data Mining, також можуть зустрічатися терміни «добування даних», «майнінг даних», «інтелектуальний аналіз даних») — це процес автоматизованого чи напівавтоматизованого аналізу великих баз даних задля виявлення корисної інформації. Це комп’ютерний метод, який використовує концепції з інформаційних технологій, статистики та математики для аналізу даних. Алгоритми глибинного аналізу даних виявляють логічні зв’язки у вигляді патернів або тенденцій у даних. Це допомагає визначати кореляції, закономірності, проблеми та слабкі місця і працювати над ними.
Статистика допомагає перевіряти гіпотези, використовуючи невеликі випадкові вибірки, тоді як глибинний аналіз даних автоматично генерує нові гіпотези, використовуючи величезну кількість даних. Штучний інтелект (ШІ) і машинне навчання також використовуються для аналізу даних.
Отже, «глибинний аналіз даних» — це не акумулювання даних, а здобуття знань із даних і формування знань. Це виходить далеко за рамки таких процесів, як оцінка ключових показників ефективності в контролінгу.
Глибинний аналіз тексту — це споріднений метод, який стосується інформації, що міститься в довгих текстових документах. Він використовує неструктуровані дані, тоді як глибинний аналіз даних зазвичай використовує структуровані дані з баз даних.
Тип тексту, який може бути проаналізований, охоплює електронні листи, нотатки обговорень, стрічки новин, вебформи, онлайнові обговорення та відповіді в довільній формі з опитувань.
Їх можна зафіксувати й отримати корисну інформацію за допомогою глибинного аналізу текстів для таких цілей, як науково-дослідні роботи, маркетинг і обслуговування клієнтів. Деякі сервіси глибинного аналізу даних підтримують функцію аналізу тексту.
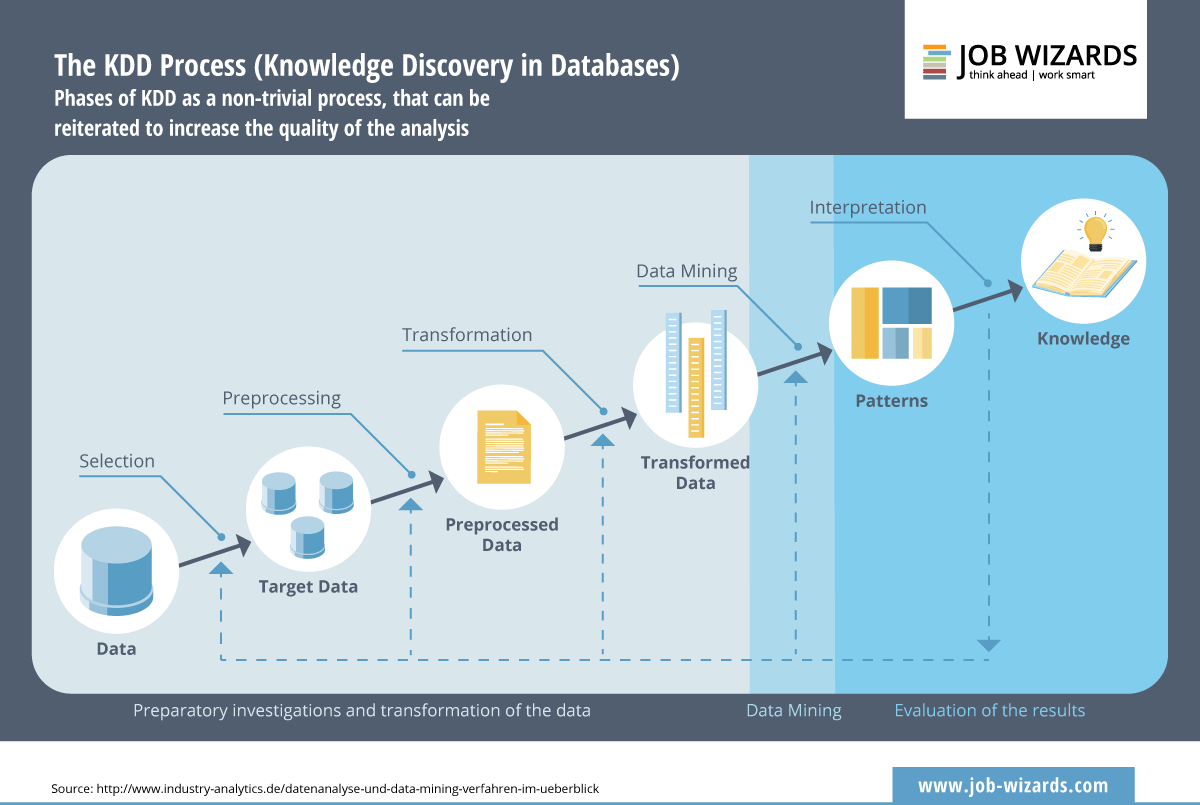
Як з баз даних добуваються знання
Комп’ютерний аналіз даних — це частина складного процесу. Фахівці з баз даних запровадили стандарт у 1989 році й назвали його «Виявлення знань у базах даних» (Knowledge Discovery in Databases, або KDD).
Ця модель спрямована на уникнення використання як джерел «примітивних наборів даних» — даних, що не містять жодних кореляцій. Фази KDD є «нетривіальним процесом», зазначають фахівці. Для підвищення якості аналізу їх можна повторювати.
KDD дає змогу отримати нові, обґрунтовані, потенційно корисні та зрозумілі закономірності, які випливають із даних.
Без Big Data глибинного аналізу не буде
Щоб скористатися глибинним аналізом даних, вам потрібні «великі дані» (Big Data), що означає велику й релевантну кількість наборів даних. Простими словами, великі дані — це такі обсяги даних, які більше не вміщаються в таблицю Excel. Excel обмежений 1 048 576 рядками та 16 384 стовпчиками.
Сьогодні дані генеруються чим і де завгодно, тож у деяких сферах бізнесу Excel можна перерости за лічені хвилини.
Для глибинного аналізу даних не потрібен якийсь конкретний обсяг даних, йому потрібні релевантні дані. А це вже вимагає великої кількості бітів і байтів. Ось чому ми впевнено стверджуємо, що великі дані — це правильне місце для глибинного аналізу даних.
Технічне тлумачення поняття «великі дані» — це систематичний збір і зберігання великих, складних, швидкозмінних обсягів даних.
Ці 6 «V» характеризують великі дані:
- Velocity (швидкість) — швидкість збору, обробки та оцінки
- Volume (обсяг) — кількість даних
- Variety (варіативність) — різноманітність складних наборів даних
- Veracity (істинність) — справжність і надійність даних
- Value (цінність) — наскільки цінні дані для бізнесу
- Validity (валідність) — забезпечення якості даних
Звичайний сервер даних не є достатньо великим для зберігання та обробки таких обсягів даних. Тож для швидкої обробки великих даних та отримання аналітики в режимі реального часу доцільно використовувати сховища даних.
CRM — чудове джерело для глибинного аналізу даних
Гарний сценарій використання глибинного аналізу даних — всебічне й ретельне документування взаємовідносин із клієнтами в системі управління взаємовідносинами з клієнтами (CRM, Customer Relationship Management System).
Можна шукати закономірності в даних, які допоможуть залучити нових клієнтів або привернути увагу клієнтів, які не проявляли активності тривалий час. У даних можна навіть знайти підказки, як повернути втрачених клієнтів.
Глибинний аналіз даних дає змогу приймати кращі стратегічні рішення. Нові знання надихнуть на нові кампанії та клієнтські програми, виробничі процеси та концепції безпеки — і не раз, а знову і знову. Якщо ви аналізуєте дані в режимі реального часу, ви набагато швидше реагуєте на тривожні сигнали та успішні досягнення.
Нові знання, отримані з даних, прямо чи опосередковано сприятимуть збільшенню продажів, а отже, і прибутку. Вони сприятимуть створенню цінності. Отримані знання допоможуть вам розробити нові продукти та послуги й навіть нові бізнесові моделі.
Ось чому використання програмного забезпечення для глибинного аналізу даних дуже корисне і важливе для малого та середнього бізнесу. Це навіть може допомогти їм втерти носа значно більшим компаніям і корпораціям.
Спершу перевірте, аналізуйте потім
Перш ніж розпочати глибинний аналіз даних, необхідно ретельно вивчити та перевірити матеріал. Дані часто нерідко збираються з різних джерел, таких як бази даних, датчики та моніторинг.
На цьому етапі оригінальні дані збираються в набори даних, що робить їх більш придатними для глибинного аналізу даних. Головне — усунути джерела помилок із зібраних даних.
Це можуть бути пропущені значення та невірна інформація. Такі дані називаються «зашумленими». Неузгодженість даних також шкодить оцінці. Вони можуть містити суперечливі значення, наприклад, вік, невідповідний даті народження.
Підготовка даних займає більше часу, ніж сам аналіз даних. Часом кажуть про співвідношення 80:20: 80 відсотків часу йде на підготовку, 20 відсотків — на аналіз. Підготовка даних для глибинного аналізу даних дуже сильно залежить від теми дослідження.
ДОКЛАДНІШЕ
- Розпізнавання відхилень: які об’єкти не відповідають правилам взаємозалежності й чому?
- Кластерний аналіз: які подібності зустрічаються найчастіше й можуть бути об’єднані в групи за цією ознакою?
- Класифікація: до яких заздалегідь визначених категорій належать ці дані, до яких вони раніше не були віднесені?
- Асоціативний аналіз: які два або більше незалежних елементи корелюють і часто зустрічаються разом?
- Регресійний аналіз: який зв’язок існує між однією залежною змінною та однією або кількома незалежними змінними?
- Прогностична аналітика: які прогнози можна зробити, спираючись на змінну?
Програмне забезпечення для глибинного аналізу даних: локальне чи хмарне
Є різні інструменти, кожен із яких має свої переваги та недоліки. Саме тому корисно використовувати більше одного інструменту для різних завдань. Хмарні продукти та веб-сервіси мають привабливу ціну, їх легко масштабувати для збільшення кількості користувачів та аналітики. Це полегшує початок роботи.
- SAS: провідний постачальник з 1976 року. Це програмне забезпечення для глибинного аналізу даних використовується низкою великих клієнтів. Воно недешеве, але добре масштабується. Графічний інтерфейс користувача робить його дуже простим у використанні.
- KNIME: Команда з Констанцького університету розробляє це програмне забезпечення з відкритим вихідним кодом із 2004 року. Нині розробка підтримується великою глобальною спільнотою розробників. Існує також комерційна версія.
- Google Analytics: безплатний і простий у використанні веб-інструмент призначений для оцінки ефективності веб-сайтів, кампаній у соціальних мережах та активності клієнтів в інтернеті.
- Periscope Data: каліфорнійський стартап успішно випустив цей хмарний сервіс на ринок. Згодом його для свого портфеля купила компанія Sisense.
- IBM Cognos Analytics: не такий відомий, як IBM Watson, але такий же розумний. Інструмент пропонує можливість самостійного обслуговування, він масштабований і може використовуватися як у хмарі, так і на локальних системах.
Розпочніть глибинний аналіз даних хоч зараз
Якщо ви вважаєте, що глибинний аналіз даних допоможе вам зацифрувати процеси та продукти, почніть із перевірки всіх наявних джерел даних. Потім потрібно перевірити якість даних: чи є вони повними, зрозумілими і правильними?
Можливо, ви захочете залучити до аналізу зовнішні джерела даних. Деякі з них, як-от дані про погоду й дорожній рух, є загальнодоступними. Інші можуть бути доступними за ліцензією. Не починайте роботу наодинці: знайдіть собі партнера для співробітництва.
Глибинний аналіз даних: один інструмент для всього-всього
У майбутньому кожен, хто працює з даними, повинен буде мати базові знання з науки про дані та вміти використовувати дані для прийняття рішень. І для цього не потрібно буде ставати експертами в програмуванні чи розробці алгоритмів.
Найважливіше, що вам потрібно як користувачеві, — це цікавість. Ваш допитливий розум ставитиме запитання, відповіді на які знаходитимуться методами глибинного аналізу даних.
Сучасні інструменти допомагають зручно візуалізувати дані. Дашборди самотужки налаштовуються так, щоби виводити для користувача саме ту інформацію, яка йому потрібна.
Тож незабаром ваша команда регулярно обговорюватиме приховані кореляції і як ними скористатися. Ласкаво просимо до бізнесу на основі даних!


